.png)
The most effective voice AI agents do more than simply relay a message. They create a conversation that feels timely, relevant, and natural to the listener.
Whether confirming an appointment, following up on an inquiry, or guiding a customer through a KYC process, their success hinges not only on the script but also on how the underlying system hears, understands, and responds in real time.
At Ukti AI, we have built voice agents that handle hundreds of such conversations every day. In doing so, we have rigorously studied, implemented, and integrated different voice AI architectures. This has given us deep insights into what makes these systems perform effectively in production.
In this article, we will explore two fundamental approaches to voice AI: cascade models and voice-to-voice models. We will examine the strengths, limitations, and engineering trade-offs of each, as understanding these architectures is crucial for anyone serious about building voice AI applications.
Inside the Core Architectures of Voice AI
While both cascade and voice-to-voice models aim to enable natural, efficient conversations, they take fundamentally different paths to achieve that goal.
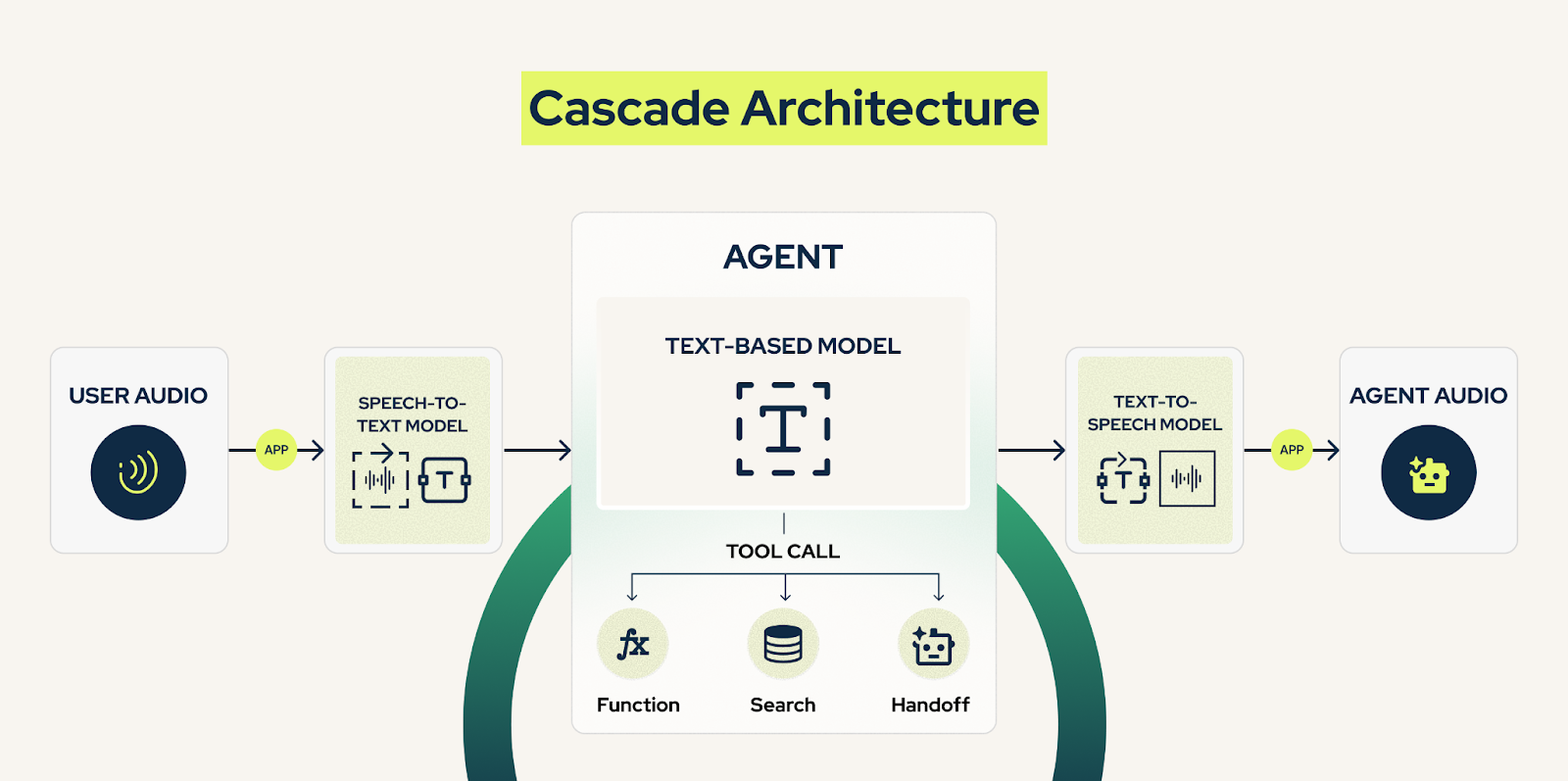
Cascade Architecture
Also known as pipeline or modular architecture, this approach breaks down voice interaction into discrete, specialized components.
How It Works:
1. Automatic Speech Recognition (ASR)
Converts audio waveforms into text transcripts using acoustic and language models.
2. Natural Language Understanding (NLU)
Processes text to extract intent, entities, and context.
3. Dialog Management & LLM Processing
Determines appropriate response based on conversation state.
4. Text-to-Speech (TTS) Synthesis
Converts response text into natural-sounding speech.
Advantage & Consideration:
The modular design makes it possible to optimize individual components without affecting the entire system. This flexibility is valuable for enterprises that want to fine-tune specific capabilities such as language accuracy or response tone. Cascade architecture also allows for easier debugging.
However, information loss occurs at each handoff point. This can make interactions feel less natural, particularly if the emotional context is important.
Voice-to-Voice Architecture
An end-to-end approach where a single model processes audio input directly to audio output, preserving the full acoustic information.
How It Works:
1. Audio Encoding
Raw audio is encoded into high-dimensional representations preserving prosodic features.
2. Multimodal Processing
A single model understands speech, language and generates responses in one pass.
3. Direct Audio Generation
Produces speech output with preserved emotional and prosodic characteristics.
Advantage & Consideration:
By maintaining audio context throughout, these models can preserve speaker characteristics, emotional tone, and conversational dynamics that cascade models inherently lose.
The trade-off is that voice-to-voice models often operate as black boxes, making them harder to debug. They also offer less flexibility for real-time adjustments compared to modular cascade systems.

The Information Theory Perspective
Not all voice AI architectures handle information equally. The way a system processes speech affects what it captures, how natural the interaction feels, and how quickly a response is delivered.
These factors are especially important in enterprise contexts, where delayed or misinterpreted responses can affect customer experience, lead conversion, or compliance workflows.
From an information theory perspective, cascade models perform multiple lossy transformations. Each stage reduces the information bandwidth:
The key takeaway here is that voice-to-voice systems preserve far more of the original audio’s non-verbal cues, which can have a direct impact on how authentic and engaging a conversation feels.
Latency Analysis & User Experience: Where Milliseconds Matter
In voice interactions, even small delays can affect how the listener perceives the conversation.
Research shows that humans perceive delays above 200ms in conversation. At Ukti AI, we've observed that reducing latency below this threshold fundamentally changes user perception from "talking to a machine" to "having a conversation."
Here’s how cascade and voice-to-voice models perform in terms of latency, based on industry benchmarks and our experience working with various providers:

By removing intermediate steps, voice-to-voice systems reduce the total time from input to response, often keeping it below the 200ms threshold where delays become perceptible.
Engineering Considerations in Voice AI
Building enterprise-grade voice AI involves more than selecting an architecture. Each approach comes with distinct technical factors that influence reliability, scalability, and performance. Understanding these considerations is essential for designing systems that deliver consistent, high-quality interactions.
API & Infrastructure Management
- Cascade: Requires orchestrating multiple API calls and managing sequential dependencies.
- Voice-to-Voice: Single API endpoin,t but requires providers with advanced capabilities.
Model Selection & Integration
- Cascade: Can mix and match best-in-class models for each component.
- Voice-to-Voice: Limited to available end-to-end models with specific capabilities.
Debugging & Monitoring
- Cascade: Clear inspection points at each stage.
- Voice-to-Voice: Black-box nature requires sophisticated analysis tools.
Language Support Dependencies
- Cascade: Depends on STT + LLM + TTS, all supporting the target language.
- Voice-to-Voice: Requires a provider with built-in multilingual voice capabilities.
API Cost Management
- Cascade: Multiple API calls per interaction can compound costs.
- Voice-to-Voice: Single API call, but typically higher per-request pricing.
Real-time Customization
- Cascade: Can adjust individual component behaviors through configuration.
- Voice-to-Voice: Limited to prompt engineering and parameter tuning.
Combining the Strengths of Both Models for Better Outcomes
Our research suggests that the future isn't about choosing between cascade and voice-to-voice models – it's about intelligent hybrid systems that leverage the strengths of both approaches. We're exploring architectures that can:
- Use voice-to-voice for emotion-critical segments while falling back to cascade for complex reasoning.
- Dynamically adjust processing based on computational resources and latency requirements.
- Maintain interpretability for business logic while preserving natural conversation flow.
- Scale efficiently across languages and domains without exponential infrastructure costs.
With this balanced approach, enterprises can adapt their voice AI systems to different operational needs without committing entirely to the limitations of a single architecture.
By selectively applying each model’s strengths, it is possible to create voice agents that are both highly capable and operationally efficient.
How Ukti AI Delivers Enterprise-Grade Voice AI
At Ukti AI, we firmly believe that it isn’t access to APIs that separates leaders from followers in voice AI applications – it’s the expertise to orchestrate them effectively.
We have invested heavily in understanding how to integrate these technologies optimally, from handling edge cases to building fault-tolerant systems. This knowledge allows us to select and combine the right services for each specific business use case, delivering production-ready voice AI applications that perform reliably at scale.
How We Do It:
- API Orchestration: Seamlessly coordinating multiple voice AI services while maintaining conversation flow and minimizing latency.
- Provider Selection: Understanding the strengths and limitations of different voice AI providers to choose the optimal stack for each use case.
- Integration Patterns: Building robust error handling, fallback mechanisms, and quality monitoring across distributed API services.
- Performance Optimization: Implementing caching, pre-warming, and intelligent routing to deliver the best possible user experience.
Final Thoughts
Designing effective voice AI requires a deep understanding of how different architectures work, how to balance their trade-offs, and how to integrate them in ways that meet enterprise demands for speed, accuracy, and reliability.
At Ukti AI, we bring the practical know-how to design, integrate, and operate voice AI that works in the complexity of real-world enterprise environments.
If you are ready to see how our approach can work for your business, feel free to book a demo. We’ll be happy to show you how our enterprise-grade voice AI agents can be tailored to your specific use case and deployed quickly to start delivering measurable results.
A cascade architecture processes speech in separate stages, such as speech-to-text, natural language understanding, and text-to-speech. Each component is specialized, allowing for modular optimization, but information can be lost during each handoff between stages.


